Implementing an Apple Health data lake using AWS
In the past I developed a solution to examine the Apple Health data download exported as an xml file. Upon reflection that only served as a stepping stone to implementing a personal data lake. A serverless application hosted in the cloud allows for much more powerful use of the data with real time insights to drive day to day decision making.
I have implemented the following solution in Amazon Web Services (AWS) which will form the basis of this blog post.
 Overview of Services Used In This Solution
Overview of Services Used In This Solution
This has been made possible due to the Health Auto Export (HAE) app which has existed since 2021. I am not the first person to make a data lake specifically in AWS using Apple Health data. Although I have taken inspiration from it I believe it is now no longer up to date with the current range of services offered by AWS. There are many points of departure between what I have implemented the referenced solution even though they are both entirely made in AWS. Only a few years ago the decision to write thousand lines of code was a necessity rather than a design decision. Now that is less the case with new manaagement console features and AWS services. Figuring out the exact mixture of services to implement for an online data lake is subjective and at the time of writing a rapidly changing environment. I have decided to make the following three factors as a priority: accessiblity to newcomers, server costs, and convenience. In practice that means I prefer to not have to write so much code where I can avoid doing so, implementing the minimum stack of services to get insights and not make calls or store files if not needed.
The major change that applies to all data lakes made now and a few years ago is the Amazon Lake Formation service being introduced and it might be the main thing that stands out at first glance.
Although I will tackle my procedure in the blog post from left to right it makes more sense for people in their own personal setups to not go about it this way. Instead they should go from the s3 bucket to lake formation then to crawling databases. This is because the automation around ingestion can be tricky for beginners as I can say from first hand experience but straightforward to understand.
Ingestion
It is worth reading the documentation for the Health Auto Exporter app. A Rest API needs to be set up for a Post Method to receive the requests made by this app. There is a 10MB cap on API exports. That effects decision making on how often to receive data and at what aggregation level. From my own testing roughly a 1MB of data can be collected for export per day. Monthly ingests like KPIs are probably not feasible with these limitations in mind. Weekly downloads might be more efficient or cost effective but a daily update would allow for timely insights so it is my preference. When it comes to configuration in API Gateway although optional it is strongly recommended to create a usage plan and an API key in order to make sure the data transfer process is secure.
In my testing the payload to JSON conversion can be tricky to examine and CloudWatch log examination can be useful to getting it right. The default timeout of 3 seconds sometimes results in the request failing. The payload structure has to be extracted according to the schema it comes written in otherwise the data will not be in the S3 buckets.
As has been noted before the data from HAE is not suitable in its raw form to be crawled. It therefore needs to be flattened to a file with one dictionary per line. One part of my Lambda function flattens the dictionaries extracted from the json data and the other part attaches the metadata back in for the crawler to pick out the fields used in querying. This is just one way to do this process flattening JSON files is a very common data preparation task
def get_meta_fields(data):
init = []
for i in range(0, len(data['data']['metrics'])):
local_dictionary = {}
unique_keys = data['data']['metrics'][i].keys()
for key in unique_keys:
if isinstance(data['data']['metrics'][i][key],list) == False:
local_dictionary[key] = data['data']['metrics'][i][key]
init.append(local_dictionary)
return init
The alternative is to use a Glue Job to relationalize the data but I prefer to potentially save money on server costs.
The actual automation part of the process takes place with triggers on the Lambda functions. Without it you are not much better off than downloading the data from Apple Health each time you want to refresh queries. During the setup process of the API you can select Lambda function as the Integration type. After writing the Lambda function that copies files from one bucket to another you can have it triggered by any upload of files in the S3 location that gets data from the API.
 Lambda function that triggers when API invoked
Lambda function that triggers when API invoked
 Lambda function that copies from one bucket to another
Lambda function that copies from one bucket to another
Validation
Beyond going over in more detail the steps to implement a data lake here is where the new and the novel comes into play for this data lake. Amazon has created a Lake Formation service which offers potentially significant quality of life improvements over the prior headaches.
Before Lake Formation you had to put in place policies, ingest data and register it separately. Fine grained control over permissions is vital for commercial applications but just as important elsewhere.
Lake Formation allows for something like a dashboard from which you can manage the location of databases, tables and permissions. The crawler is the final part of the automation. You can have it run every day in order to make sure queried data collected throughout the day on your Apple Watch shows up in a query made at the end of the day.
Querying and Visuals
If all the steps have been followed correctly the tables should automatically be populated with all the fields that can be queried using SQL in Athena. Moreover you can form a dashboard that neatly sits right on top of these queries that automatically refreshes with new data.
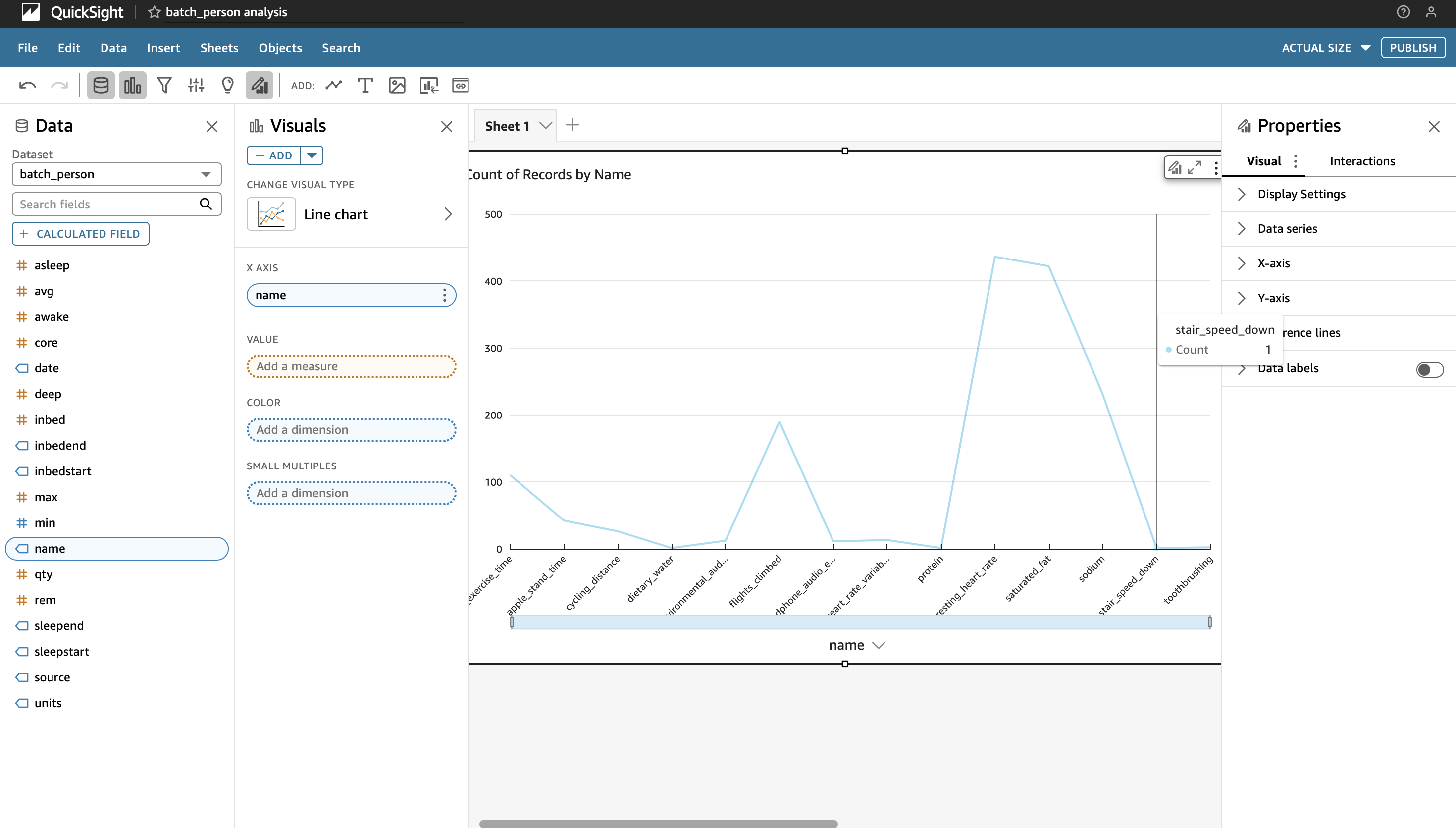 Frequency Chart
Frequency Chart
Miscelleneous
If this process is daily it can take a while for your buckets to fill. Here is where I have to confess my own limitations. I don’t know if historical data should be dumped in one big file or in small uploads containing a days worth of historical data at a time. Or perhaps bypassing the app and dragging and dropping the files from the direct download taken from the Apple servers.
 Bulk Ingest on iOS
Bulk Ingest on iOS
For each of the many services mentioned in this blog post it is important to have permissions to access the objects and files otherwise you will encounter errors. I found the IAM Policy Simulator helpful for troubleshooting just like the aforementioned CloudWatch.
Credit for much of the framework of this data lake is owed to Johnny Chivers and his content on AWS. I am omitting export to parquet at this stage because this is not truly big data and I doubt it will ever be. In terms of the bronze-silver-gold pipeline I have considered the landing point for API data to be bronze. After flattening the JSON data to be crawler ready the transformation has made it silver. Because there are no external users of this data I don’t think there will ever be a gold bucket.
Final Thoughts
I have given a title for this post of Apple Health data lake. In the future I will hope to add another source of data which is the Apple Health workout data. This is just the beginning. It may well be worthwhile to look into implementing endpoints to collect data from Withings, Strava, and elsewhere to expand this into more of a health lake. From there it might be worthwhile to make something similar to exist.io which would make this more of a personal records data lake.