Updated Health Lake Architecture
Where Was I?
After a few months away I’m back. Hope you didn’t miss me. It is hard to tell since I do not have comments enabled but I could look into adding them some time later. By now you know what this blog is about but if not you can read the earlier posts.
Architecture
What Changes Have I Made and Why
Let’s start with how the solution diagram currently looks and what has changed.
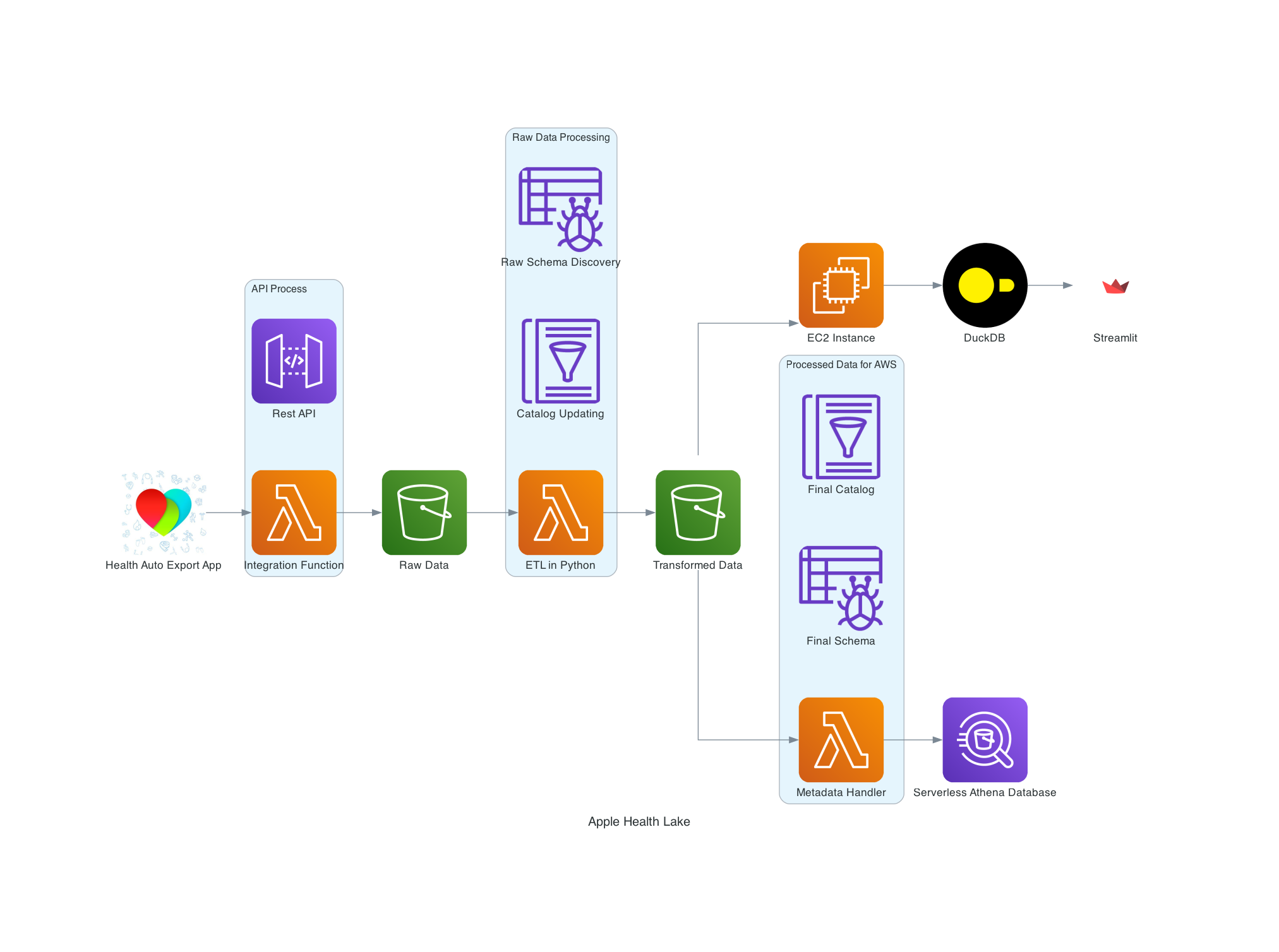 Health Lake Revision
Health Lake Revision
As this project concludes for the foreseeable future the core AWS services I see myself sticking with are S3, Lambda, API Gateway and EC2. I prefer to use universally understood services that have stood the test of time over niche platform specific ones like Glue Studio, Lake Formation, QuickSight. That makes this architecture portable to other cloud providers potentially if a migration happens and it makes what I have more extensible to other projects perhaps in a commercial setting.
The solution diagram represents two flows of data one for health records and the other workouts. Currently I have a data lake that is functional but a little rough around the edges. One dashboard is meant to serve as a Strava clone and another sheet proposed in the future to be an Apple Health clone. There is only a Strava clone right now which I have a screenshot for but you can use your imagination to think of an Apple Fitness clone that aggregates and gives daily averages for things like steps taken, resting heart rate and heart rate variability. I already deployed my Streamlit dashboard with one page from a script cloned from a Github repository and do not want to modify it again. The Streamlit dashboard can use some love in terms of presentation and I might do some other things like buying a web domain rather than access an IP address. The dates and times look odd which I will address later.
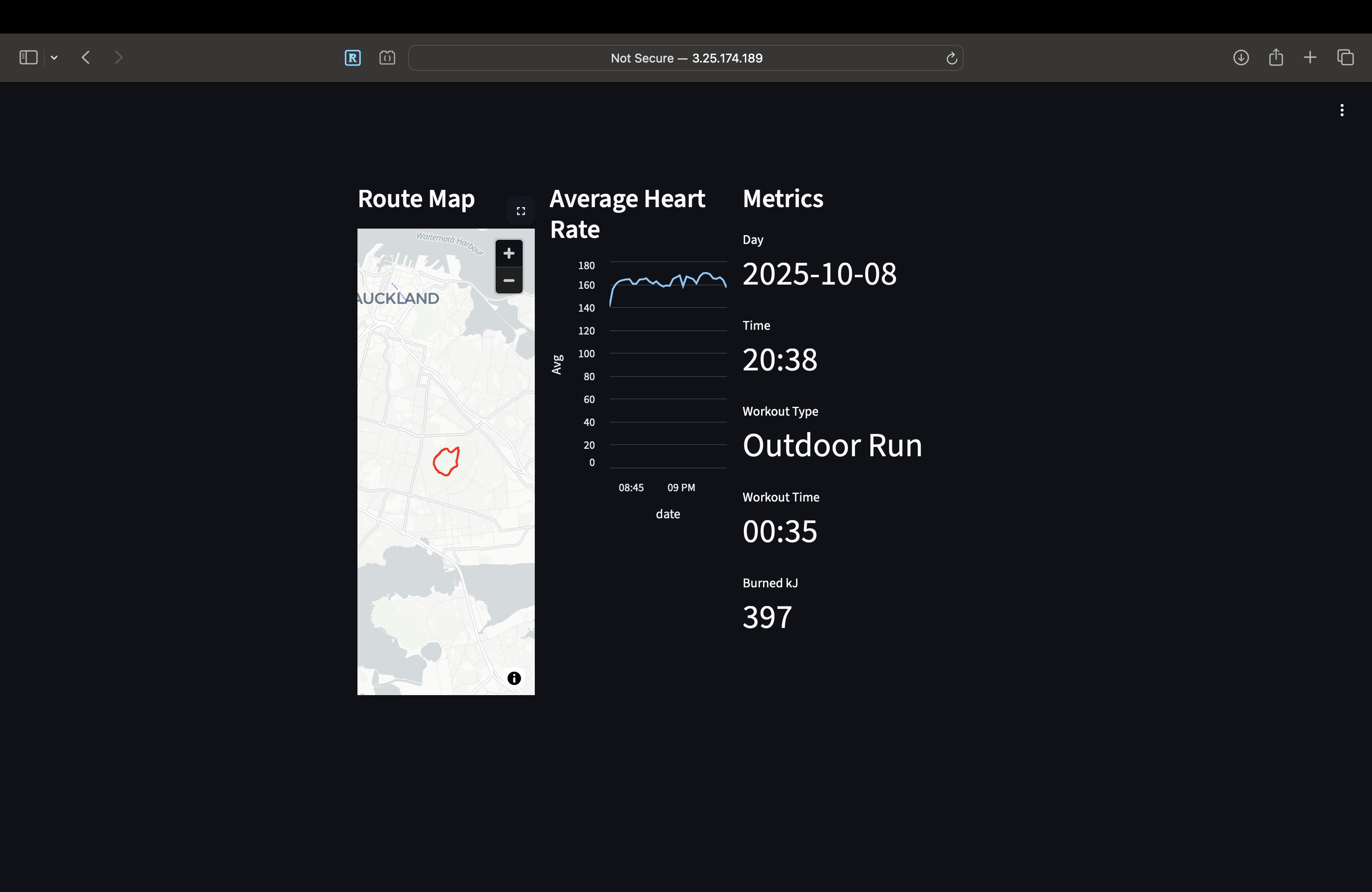 Strava-Like Map, Heart Rate, Metrics
Strava-Like Map, Heart Rate, Metrics
Adventures and Misadventures With Glue
What precipitated the main change in the architecture was how I did my ETL. Earlier I would use Glue running PySpark but now I no longer use it. The first practical reason was that my Glue jobs were writing duplicate files in the same partition output folders. I learned that I can modify my PySpark script to not have this happen with deduping done in advance. However I was frustrated there was no out of the box solution here and that I would have to look further into the documentation for something that I do not think warrants that attention.
Secondly it has been said that Python and SQL are the language of data science and I subscribe to that belief. Once one accepts that it is difficult to reconcile having to learn about Scala, JVMs and managing clusters. That I feel is the domain of software engineers and something I never want to touch unless it is needed. Computers now are extremely fast and performant compared to when these technologies were introduced so some of the old (in technology time scales) wisdom might be out of touch. So what have I done? I convert the files to parquet using Lambda functions. There are parquet writers in Lambda using pandas which is what I ended up using. It is not a completely frictionless experience however. The computation here can be heavy because I am ingesting raw JSON files that are often 3-5MB and there can be some time for Lambda to start up when it has to import all of these modules that do not come without Lambda layers. Therefore I had to fiddle around with the minimum system requirements for time allocation and memory because otherwise I risk being timed out.
These Lambda functions then become no longer as cheap as bare minimum exemplars often are that that use 3 seconds of execution time and basic Python modules. I have not run the calculations precisely but I am almost certain I will be ahead in terms of costs because Glue jobs require starting up a cluster and in my experiene they take longer than the few seconds it takes for my Lambda functions to run.
Another change worth discussing is the use of DuckDB. I try to err on the side of using the more modern tool where available for a project where it is optional to demonstrate that this implementation is unique to me at this moment rather than reheated work someone else may have already done years ago. I was aware of DuckDB before but what helped push me over the edge were articles like this one. My observation is that professionals in this space like to wow clients with flash both for professional advancement and for personal curiosity. That leads to mismatches when it comes to actually creating something that works on a small scale for personal use. There is an invisible force drawing you in to complex, expensive tools that are not required.
With Athena you pay per query but DuckDB uses your own hardware so it is essentially free locally but in the cloud you have to pay server costs. I see that as an improvement when it comes to ad hoc analysis but with dashboards it might end up being about the same. With DuckDB you do not need Glue Data Catalog (AWS metadata) to make queries because it is not an AWS service rather a third party service that connects to an S3 location. That raises the question of why I am creating Glue Crawlers and incrementally updating Glue Data Catalog. That brings me to the next section.
Data Lineage
If I am just dumping raw JSON into S3 buckets to transform to parquet that gives me no data lineage. To find out what is going in and out and when there is always CloudWatch logs but for older records that is not sufficient for me. This is important because I see myself hot swapping data on an ongoing basis. The IOT data sources I am relying on do not just consist of the Apple Watch but also my Withings Sleep Mat and Withings Smart Scale. Those data payloads do not appear in Apple Health without opening the Withings app on my phone and thereby triggering automatic sync. As a result I am always going to be taking out incomplete data and swapping in updated data for this cloud architecture to have everything available. As a result metadata of when the data was ingested for example the day after it was recorded or some time later matters. Originally not knowing much about this whole subject (and still floundering) I thought the solution would be a lakehouse (they’re all indistinguishable for my purposes but I was considering Iceberg). Even better that this is shiny and new like DuckDB. Before I knew the difference between OLAP and OLTP databases I was going to make a lakehouse but having now been enlightened that I am creating something that is OLAP the lakehouse approach was not for me. I will make do not having transactions of database changes but instead have the data lineage systems to know what data came in and when.
Medallion Architecture Redux
Another article influential on my way of thinking was this one. Discovering that medallion architecture is not some pattern that has been around for decades (if you had asked me to guess I would say late 1990s) but started around mid 2020 was eye opening. My conclusion is that medallion architecture has been oversold and is not needed for most projects even at commercial scale. Henceforth I only have two layers to my data either processed and unprocessed or raw and curated. If I do not have a gold section to my data lake does that mean that my dashboards query my entire database leading to expensive overhead? Not quite. DuckDB can searches through S3 locations. At whatever time period my dashboards aggregate over (monthly is easiest for illustrative purposes) I use my Streamlit python script to check what date it is currently then use that to get a regex pattern of where the DuckDB should be pointed to to only get the data relevant to the current dashboard in table format. For example this string ‘s3://bucketname/objectfoldername/partitionname=2025-10-/.parquet’ gets the current months data at time of writing.
I was even questioning having both a raw and curated layer. If data is only going to be queried once processed why keep the high cost data storage json? Well that concern went from theoretical to practical with my date time bug.
Pandas Parquet Problems
A bug I encountered when undertaking the ETL operation mentioned above is that when you convert timestamp strings to timestamp type is that Python does not infer the time zone of the timestamp string input which means the output is of a time zone completely different to what was inputted unless you get lucky and live in UTC anyway. This was never a problem when doing type conversions in Glue so maybe that was why my guard was down. I only noticed this error after writing dashboard code. That shows to me the simplicity I thought I was getting switching out ETL with PySpark and Glue to Lambda and Pandas was partially an illusion. The time gained in simplicity of the tool involved can and here was lost debugging and fine-tuning.
Ideas Graveyard
Before doing some things incorrectly I never appreciated why they were wrong. One example is combining data from my xml file as the backfill and making use of HAE data for future data uploads. If the data is already there and exportable from the one HAE source it makes no sense to try and merge data this way. Similarly I used HIVE style calendar partitioning which I conceived to be better for folder navigability on the visual UI of AWS Management Console. Instead now I know that string date partitioning makes the most sense since it prunes the amount of partitions created and generally reduces complexity when it comes to Glue PySpark ETL jobs where partition keys become multiple. That is a moot point now because I am not using Glue ETL. I sometimes look at these lessons learned and cringe but it at least shows that I am growing and everyone has to start somewhere.
Python Diagrams
The architecture revision extends not only to my Health Lake but to how I do diagrams. In the past I used point and click interfaces just to create something but I much prefer the repeatability and precision of using diagrams generated from code written in Python using the diagrams module.
Unresolved Issues
While writing this post I am still not quite sure of what is best when it comes to architecture on a couple of points because multiple things work but it is hard to guage what is good without feedback from team members or the community. One is whether the initial crawl should be on the backfill data already there in the raw folders. The other is whether the stitch up job I did on bad ETL data should be on transformed data in situ or reprocess the entire raw data layer from scratch one at a time.
App Talk
The HAE app is not as reliable as I would like. I have had months where things run flawlessly in the background then when it came to refining for this blog post the POST request uploads becomes intermittent. I have had to figure out on my own that uploads don’t seem to happen if you have a VPN running. In addition it is easy to forget that uploads need a stable internet connection which might not be possible depending on your current circumstances.
AI Coding Help
I used ChatGPT and Claude for coding help on all the lambda functions and the streamlit app. People get hung up on how LLMs are inadequate when they write code that does not work. I think the bigger problem is code that passes the LGTM test but silently is a breaking change you only notice later. That takes longer then to debug and dissolves the illusion of productivity gains. If I commit something that causes errors from AI code I want it to fail spectacularly not pass and be inadequate without me even knowing.